
Table of Contents
What is a validation metric?
A validation metric is a formula we use during model validation to confront the model predictions with the actual output values.
The choice of a validation metric depends on the type of the problem.
Validation metrics for regression problems
I’ve found the code for the metrics in the Sklearn documentation.
Mean absolute error (MAE)
The absolute error is the mean of the differences between the actual values and the predicted values of the validation set.
Where:
- N is the number of samples in the validation set,
- y is the actual value,
- predicted y is the predicted value.
Flaw
The mean absolute error seems simple and efficient. But it has a flaw.
If predicted_y > y, the absolute error is negative, and vice-versa. So, when we sum all the absolute errors to compute the mean, negative values cancel out positive values.
Python implementation
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(val_y, model.predict(val_X))
Mean squared error (MSE)
To solve the MAE issue, we have to square the subtraction, in order to have all positive values.
Flaw
Let’s say we are working with a real estate dataset, where the price of the properties are the labels. When we calculate the MSE, we get in return the squared values of values with 6 or 7 zeros. This number is huge and difficult to interpret.
Python implementation
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(val_y, model.predict(val_X))
Root mean squared error (RMSE)
To “counter” the exponents’ magnification effect, we can calculate the square root of the MSE.
Python implementation
from sklearn.metrics import mean_squared_error
import math
rmse = math.sqrt(mean_squared_error(val_y, model.predict(val_X)))
Validation metrics for classification problems
Positive and negative outputs
In a classification problem, there are 2 types of labels, positive and negative.
Positive outputs are labels with a particular characteristic that we are interested in. All the other labels are negative.
For example, in a dataset of cancer diagnoses, the positive outputs are precisely the carcinogenic ones, the ones we are interested in.
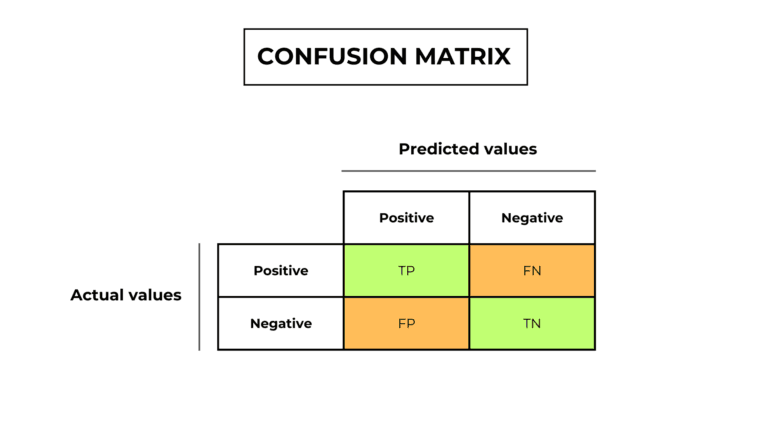
True and false predictions
We can identify 4 types of predictions:
- True positives (TP): correct positive predictions
- False positives (FP): incorrect positive predictions
- True negatives (TN): correct negative predictions
- False negatives (FN): incorrect negative predictions
Accuracy
Accuracy is the ratio of correctly predicted instances to the total instances in the dataset.
It answers the question “Of all the predictions, how many are correct”
Flaws
Imagine we have a dataset with scans of patients’ brains. This is a rare disease and consequently, our dataset has many more negative examples than positive ones.
Unfortunately, our model has not been well-trained. It classifies healthy brains well but has problems with positive outputs. During validation, since the positive observations are much fewer, the overall accuracy is high even though our model isn’t well trained.
To counter this, we should use accuracy when our classes are relatively balanced in the dataset.
Python implementation
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(val_y, model.predict(val_X))
Precision
Precision is the ratio of correctly predicted positive instances to the predicted positive instances. It answers the question: “Of all instances predicted as positive, how many are positive?”
Python implementation
from sklearn.metrics import precision_score
precision = precision_score(val_y, model.predict(val_X))
Recall
Like precision, recall is a metric for a specific label.
It expresses the ratio of predicted positive outputs to all the positive outputs. It answers the question: “Of all actual positives, how many were correctly predicted?”
If the recall of an output value is high, our model is good at recognizing that label.
Flaws
If our model classifies all outputs as positive, the recall is 1 (perfect). To address this issue, we must also calculate the precision; high precision ensures that recall is meaningful.
Python implementation
from sklearn.metrics import recall_score
recall = recall_score(val_y, model.predict(val_X))