
Table of Contents
What is feature engineering?
Feature engineering is selecting, extracting, and transforming features from raw data to create a new dataset useful for building predictive models.
This new dataset is compatible with our algorithm and provides the model with more valuable information, consequently improving its efficiency.
Why is feature engineering important?
Data is the core of machine learning. Artificial intelligence models structure depends on the data they are trained on.
When machine learning scientists have to work with a company, the data they have available isn’t perfect. There are null variables, data types incompatible with ML models, disorganized features, outliers, etc…
We must start building our model with the most meaningful and most organized dataset possible.
Some feature engineering techniques
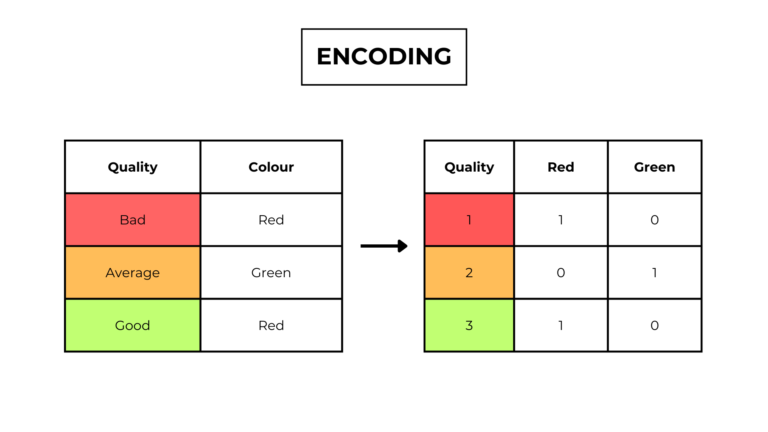
1. Encoding categorical features
Since machine learning algorithms are based on mathematical formulas, they can’t understand texts.
To solve this issue we can:
- Drop the categorical feature.
- Assign each category a number (ordinal encoding).
- Generate a new feature for each category, assigning a value of 1 or 0 based on the original value (one-hot encoding).
- …
* Which way is the best? Are there other ways to solve this issue? Full article here.
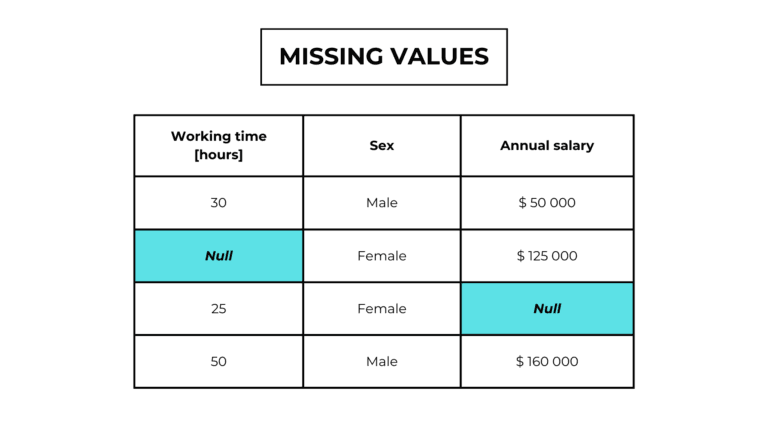
2. Handle missing values
Missing values are the absence of an observation. In a dataset they are labeled as “null” or “Nan”.
Machine learning algorithms can’t work with these values. We have to solve this issue, we can:
- Eliminate the samples with a missing value.
- Eliminate a feature with a lot of missing values.
- Replace the missing values with something (imputation)
ex. mean value of the feature.
Which way is the best? Are there other ways to solve this issue? Full article here.
3. Normalization
Let’s say that in a numerical feature, we have the possible values in a range between 350 and 1450. Normalization allows us to squeeze these values between 0 and 1.
This technique is useful when we want to compare features on different scales. The formula for normalization is:
new_x = x – min / max – min
Where:
- new_x is the normalized value,
- x is the value,
- min is the minimum value,
- max is the maximum value.
4. Standardization
Standardization is a technique to transform each feature to make the mean value 0. Like normalization, standardization helps us confront the values between features.
new_x = x – μ / σ
where:
- new_x is the standardized value,
- x is the original value,
- μ is the mean of the feature,
- σ is the standard deviation of the feature.