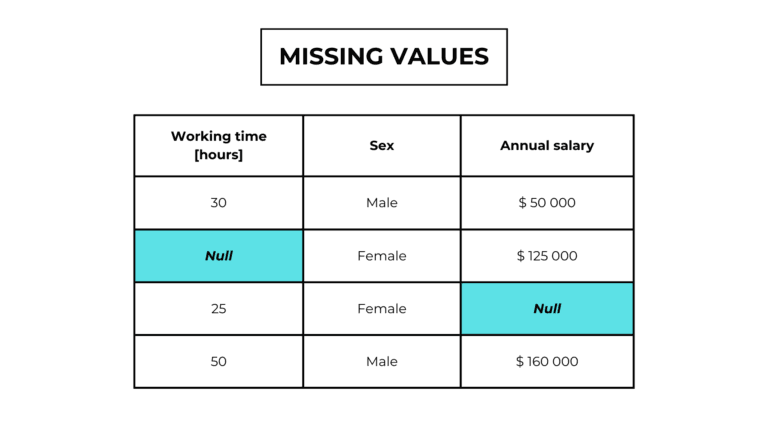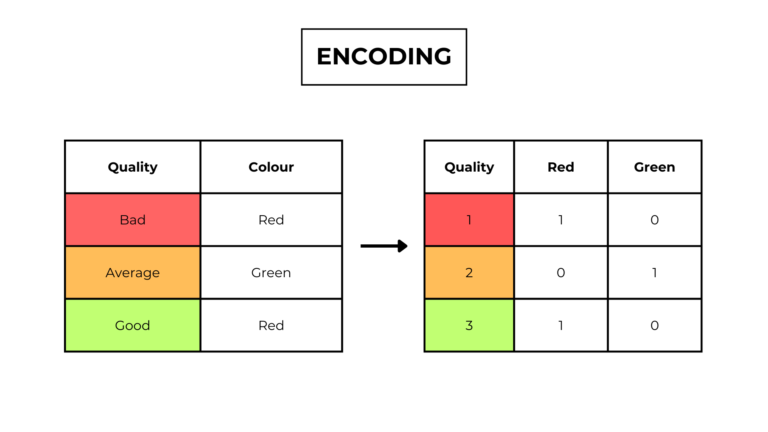

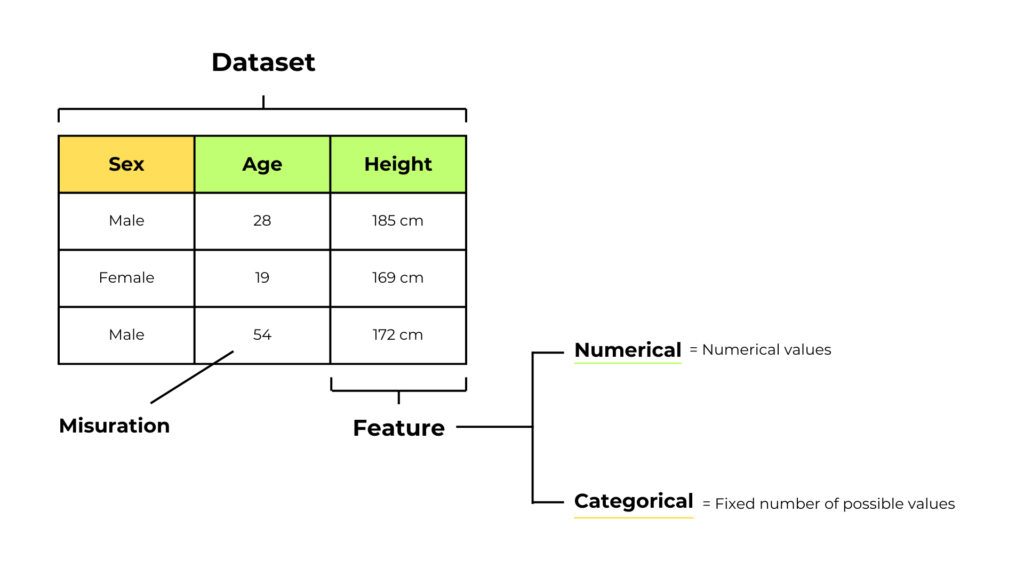
In machine learning, we can identify data as a set of observations or measurements, called dataset, used to train and test a machine learning model.
Data are crucial because artificial intelligence is built on them, and their quantity and quality drastically affect the accuracy of our model.
Table of Contents
Data collection
Data collection is the process of collecting data from various sources.
When I start machine learning projects generically I search on Kaggle, a huge machine-learning community on which you can find high-quality datasets on various topics.
Dataset and features
We said that the set of information useful for developing our algorithm is called a dataset.
But in the latter, how is it structured?
It cannot be amassed without a defined structure, otherwise neither a human nor a machine would understand anything about it.
The dataset is organized into features (or variables): a subset of observations about the same phenomenon or characteristic of something.
| Sex | Age | Height |
|---|---|---|
| Male | 28 | 185 cm |
| Female | 19 | 169 cm |
| Male | 54 | 172 cm |
In this medical dataset, we have 3 different variables.
Types of features
By reading the previous example, we can see that some features are different.
Numerical features
For height or age, the values are numeric and limitless. Features like this are called numerical features.
Categorical features
Meanwhile, for sex, the data in this feature can assimilate a number of limited and fixed values. Features like this are called “categorical features” and the possible values “categories“.
There are 2 types of categorical features:
- Ordinal data have a qualitative order.
ex. bad, mid, good… - Nominal data don’t have a qualitative order.
ex. red, green, blue…
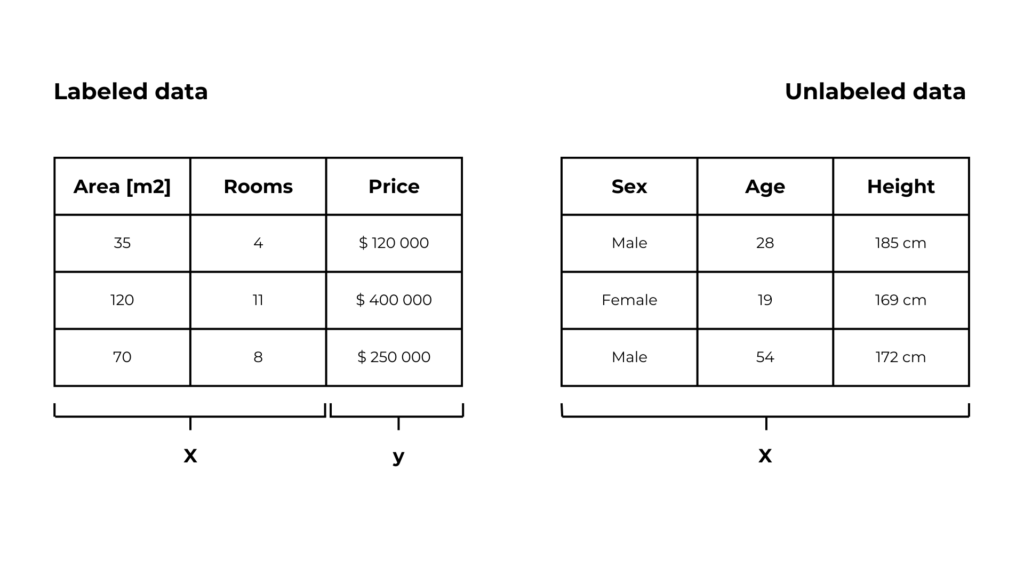
Labeled data vs unlabeled data
Labeled dataset
In a labeled dataset each input data is assigned an output (label).
These outputs are in the target (or output) feature.
We want to build a model that can predict the output value given an input observation. This approach is called supervised learning.
Unlabeled dataset
In an unlabeled dataset, there is no output feature.
This means that we can only use an algorithm that finds a meaningful pattern between the input data. This approach is called unsupervised learning.
Feature engineering and data split
Before we input our dataset into our model we have to follow two steps:
- Feature engineering, the main argument of this blog’s section.
- Data split, the process of splitting the datasets into 2 smaller datasets, used for training and validation.