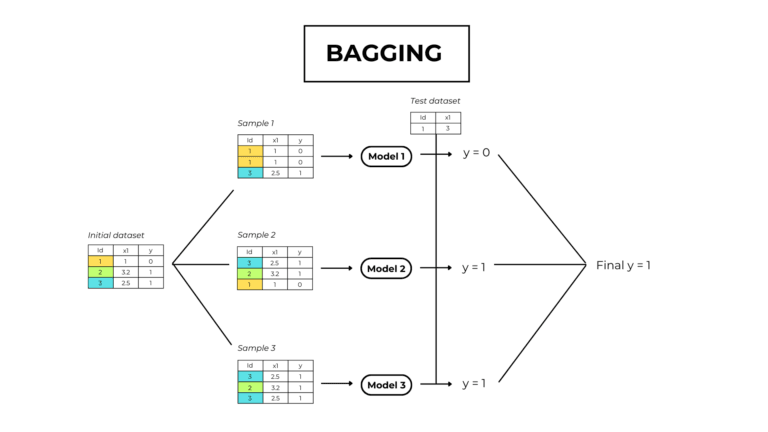
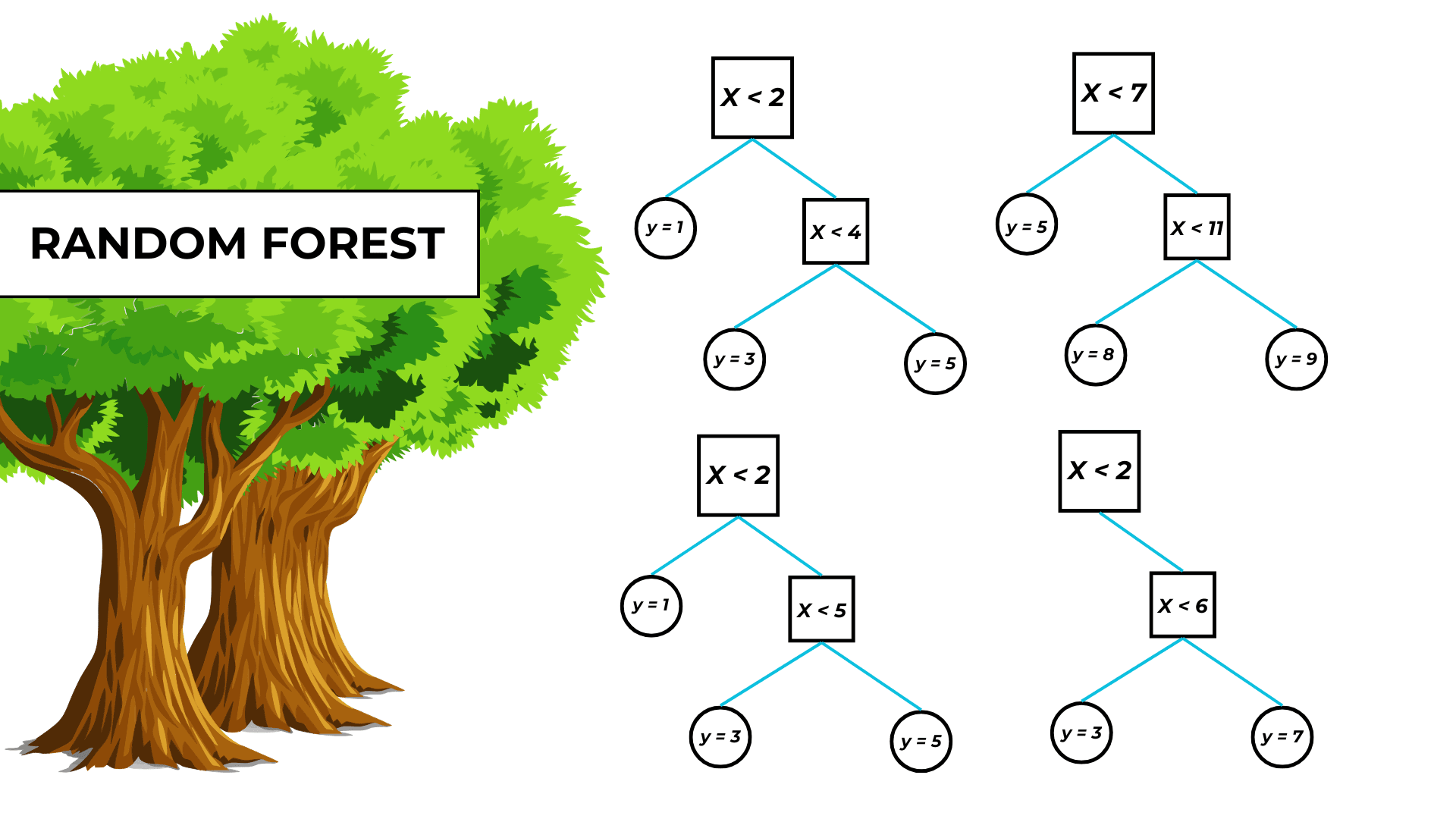
In this post, I’ll show you how to program a random forest from scratch in Python using ONLY MATH.
Table of Contents
Why is coding a random forest from scratch useful?
When studying a new machine learning model, I always get lost between the formulas and the theory, and I don’t understand how the algorithm works.
And there is no better way to understand an algorithm than to write it from 0, without any help or starting point.
Disclaimer
To understand this article you should read:
- The complete article I made about random forests, where I explain clearly how this algorithm works.
- The article on how to program a decision tree from scratch, which I’ll use in this code.
Random forest from scratch in Python
Problem statement
We want to solve a regression problem training a random forest algorithm.
1. Import necessary libraries and code
import numpy
As you can see, my titles aren’t clickbait.
In this code, I use only numpy to handle lists better.
2. Define the dataset
X = [0.5, 0.7, 1]
Y = [1, 1.5, 1.8]
I use a dictionary structure to store my dataset about house prices.
3. Import decision tree building code
# import decision tree code
4. Define the training function
def build_ensemble(train_X, train_y, n_estimators, max_depth):
ensemble = []
for n in range(n_estimators):
#boostrapping
datapoints = list(numpy.random.choice(range(len(train_X["LotArea"])), size=len(train_X["LotArea"]), replace=True))
bootstrapped_X = {}
bootstrapped_y = {}
for feature in train_X.keys():
bootstrapped_X[feature] = [train_X[feature][datapoint] for datapoint in datapoints]
bootstrapped_y["SalePrice"] = [train_y["SalePrice"][datapoint] for datapoint in datapoints]
print(bootstrapped_X)
print(bootstrapped_y)
#train a tree on the new dataset
tree = create_node(bootstrapped_y, range(len(bootstrapped_y["SalePrice"])))
build_tree(bootstrapped_X, bootstrapped_y, tree, max_depth)
print(tree)
ensemble.append(tree)
return ensemble
The build_ensemble function takes in input the number of weak learners and iterates through it. At each step, the function does 2 things:
- Generate a copy of the training dataset by randomly selecting samples (bootstrapping).
- Train a tree on this new dataset.
5. Define the prediction function
def ensemble_predict(val_X, ensemble):
y = []
# aggregation
for index in range(len(val_X["LotArea"])):
predictions = []
new_input = {key: [value[index]] for key, value in val_X.items()}
for tree in ensemble:
predictions.append(predict(new_input, tree))
y.append(numpy.mean(predictions))
return y
The model prediction is the mean value of the predictions of its trees (aggregation).
6. Train a random forest on the dataset
ensemble = build_ensemble(X, y, 3, 2)
Our model looks like this:
[{'datapoints': range(0, 3), 'mean_value': 128.33333333333334, 'mean_variance': 1338.888888888889, 'leaf': False, 'feature': 'LotArea', 'treshold': 70, 'left': {'datapoints': [1, 2], 'mean_value': 102.5, 'mean_variance': 6.25, 'leaf': True, 'feature': None, 'treshold': None, 'left': None, 'right': None}, 'right': {'datapoints': [0], 'mean_value': 180.0, 'mean_variance': 0.0, 'leaf': True, 'feature': None, 'treshold': None, 'left': None, 'right': None}},
{'datapoints': range(0, 3), 'mean_value': 155.0, 'mean_variance': 1250.0, 'leaf': False, 'feature': 'LotArea', 'treshold': 70, 'left': {'datapoints': [0], 'mean_value': 105.0, 'mean_variance': 0.0, 'leaf': True, 'feature': None, 'treshold': None, 'left': None, 'right': None}, 'right': {'datapoints': [1, 2], 'mean_value': 180.0, 'mean_variance': 0.0, 'leaf': True, 'feature': None, 'treshold': None, 'left': None, 'right': None}}]
I know a first it seems complex, but if you study this text carefully, EVERYTHING MAKES SENSE!
7. Make predictions!
val_X = {
"LotArea" : [50, 90],
"Quality" : [7.5, 9]
}
print(ensemble_predict(val_X, ensemble))
[103.75, 180.0]
Let’s go! These predictions make sense.
Random forest from scratch full code
import numpy
X = {
"LotArea":[50, 70, 100],
"Quality":[8, 7.5, 9]
}
y = {
"SalePrice":[100, 105, 180]
}
# import decision tree code
def build_ensemble(train_X, train_y, n_estimators, max_depth):
ensemble = []
for n in range(n_estimators):
#boostrapping
datapoints = list(numpy.random.choice(range(len(train_X["LotArea"])), size=len(train_X["LotArea"]), replace=True))
bootstrapped_X = {}
bootstrapped_y = {}
for feature in train_X.keys():
bootstrapped_X[feature] = [train_X[feature][datapoint] for datapoint in datapoints]
bootstrapped_y["SalePrice"] = [train_y["SalePrice"][datapoint] for datapoint in datapoints]
print(bootstrapped_X)
print(bootstrapped_y)
#train a tree on the new dataset
tree = create_node(bootstrapped_y, range(len(bootstrapped_y["SalePrice"])))
build_tree(bootstrapped_X, bootstrapped_y, tree, max_depth)
print(tree)
ensemble.append(tree)
return ensemble
def ensemble_predict(val_X, ensemble):
y = []
# aggregation
for index in range(len(val_X["LotArea"])):
predictions = []
new_input = {key: [value[index]] for key, value in val_X.items()}
for tree in ensemble:
predictions.append(predict(new_input, tree))
y.append(numpy.mean(predictions))
return y
ensemble = build_ensemble(X, y, 2, 2)
print(ensemble)
val_X = {
"LotArea" : [50, 90],
"Quality" : [7.5, 9]
}
print(ensemble_predict(val_X, ensemble))