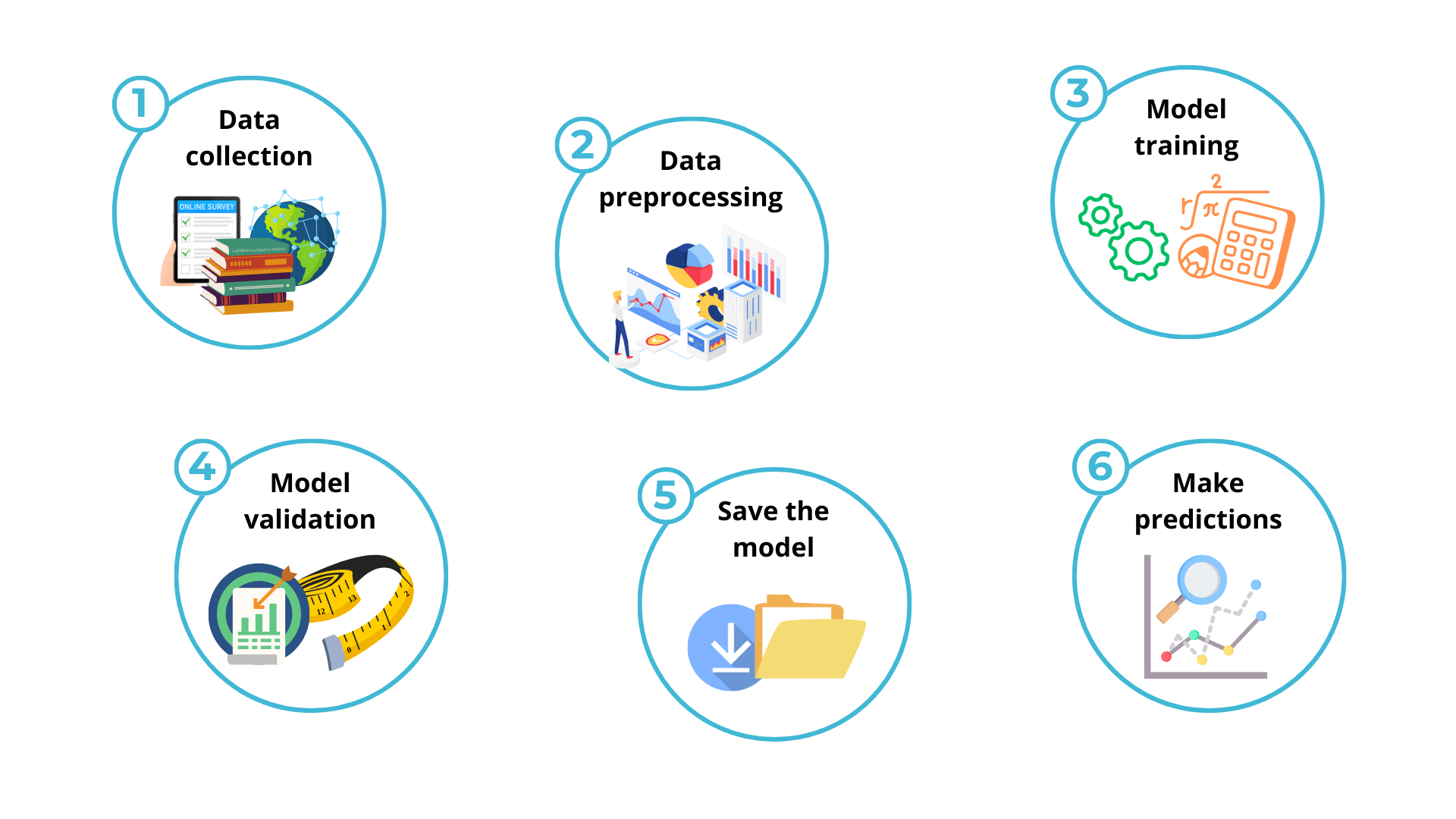
This article explains the steps to build a machine learning model, including explanations, examples, and Python code that everyone can try to execute and modify as they like.
Table of Contents
In this article, I will use the following Python libraries to make the programming of our model more automatic.
import pandas as pd
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
import joblib
1. Data collection
Data collection is the process of collecting data from various sources. In addition to accumulating data, we must structure it so that a program can manage and process it.
However, this structure depends on the data we have available and the nature of the problem we need to solve.
For example, for a house value prediction, data about the building would be organized in a table that looks something like this. Since this is a regression problem (supervised learning) we have input columns, like area and n. of bedrooms, and output columns like the price.
| Index | House area in m2 | Number of bedrooms | Number of bathrooms | Price |
| 1 | 200 | 2 | 1 | … |
| 2 | 300 | 3 | 3 | … |
| … |
If the problem we need to solve requires an unsupervised learning approach, the data will not be labeled, that is, it will not have an output column (i.e. label).
| Index | Sex | Age | Height |
| 1 | Male | 30 | 185 cm |
| 2 | Female | 23 | 167 cm |
| … |
Data collection is crucial for building a model because the better the quality of input data the better accurate the predictions in real-world scenarios.
2. Feature engineering
After collecting all the data, we need to focus on feature engineering, the process of transforming raw data into a format suitable for training and testing our models.
Some common data preprocessing techniques are:
- Handling missing values
- Transforming (or encoding) categorical values into numerical ones
- Creating new features by combining existing ones
- Choosing the most relevant feature for the prediction (feature selection)
# the path of the file with the data
file_path = "C:\\...\\data.csv"
# tell Python to read and understand the table
table = pd.read_csv(file_path)
# remove columns with missing values (there are other methods to replace them)
table = table.dropna(axis=0)
# select only the x variables affecting the y
table_variables = ["variable1", "variable2"...]
# X = all the useful variables
X = table[table_variables]
# y = the varialbe of the table we want to predict
y = table[["Price"]]
# divide the training data from the validation ones
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 1)
3. Choose a model
4. Model training
Training is the actual learning phase of the model.
We feed the model with previously selected and processed data, and through mathematical algorithms can iterate between data points and modify its structure.
# after defining the variables, we first decide what model we want to use, in this case a # decision tree and then we train it using the training X and y
model = DecisionTreeRegressor()
model.fit(train_X, train_y)
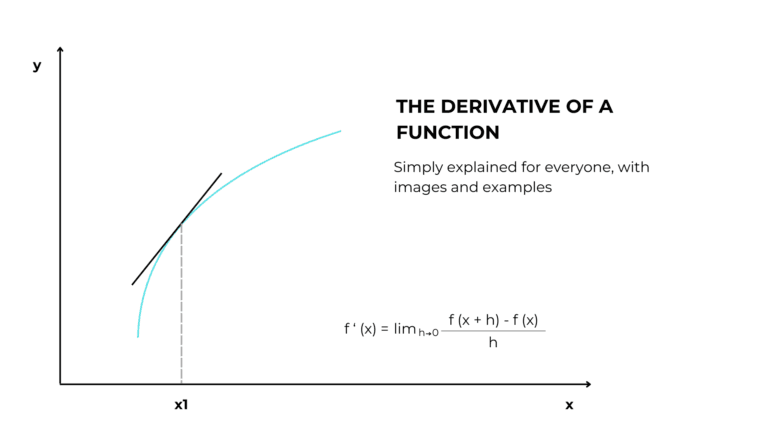
For those interested in finding out how a machine can learn, I have written this article with examples that is within everyone’s reach.
5. Model validation
Model validation is the evaluation of a model’s accuracy and reliability.
To do this we must first have the model predict the values in the subset for testing, on which it has not been trained.
Then we compare the model outputs with the actual values according to various parameters, such as:
Mean absolute error
The mean value of the absolute differences between predicted and actual values. Used for regression.
Mean squared error
The mean value of the squared differences between predicted and actual values. Used for regression.
Accuracy
The number of correctly predicted values is divided by the number of the total samples. Used for classification.
Precision
The number of actual positive values is divided by the number of positive predictions.
7. Make predictions
Now that our model is trained, it’s ready to make predictions.
print(loaded_model.predict(...))