Table of Contents
Bias and variance are 2 fundamental metrics to describe a model’s ability to resolve a problem.
Let’s say we have a dataset like this one.
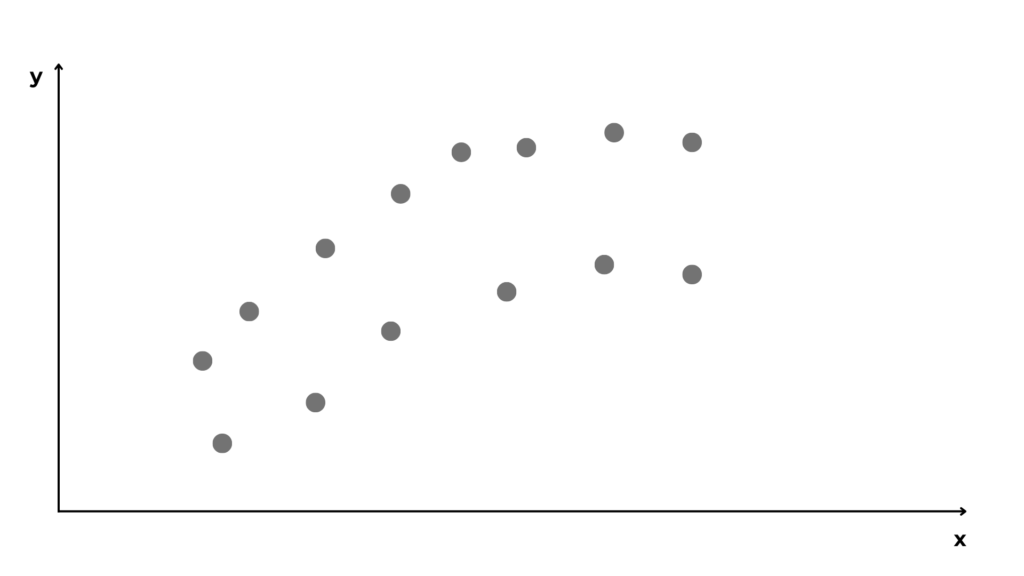
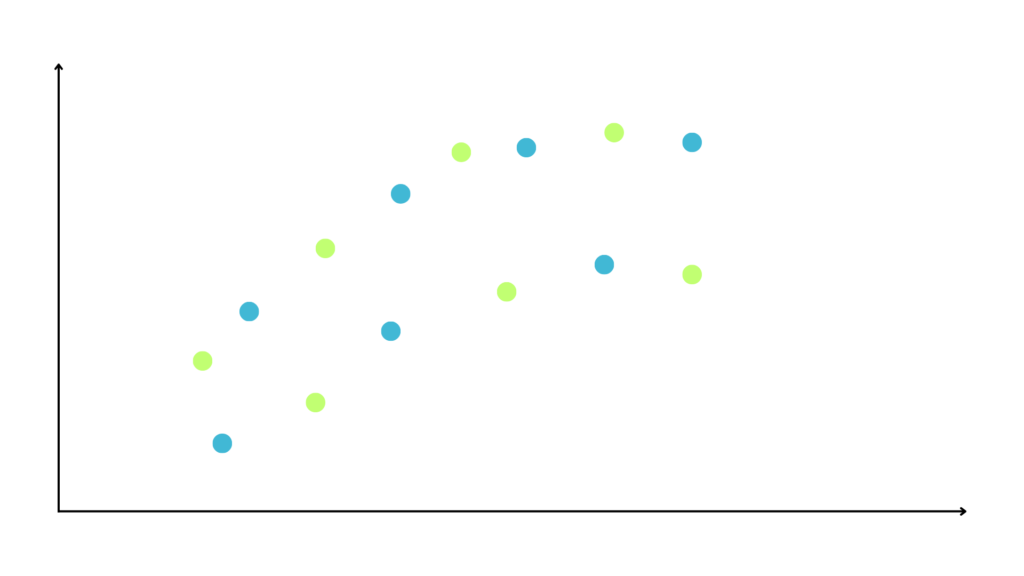
We want to represent the relationships between the x and y to predict new values. To do this we first split the dataset into training and testing sets.
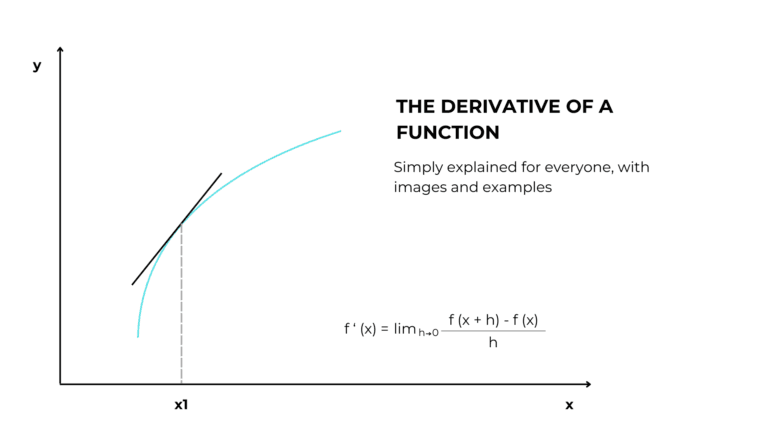
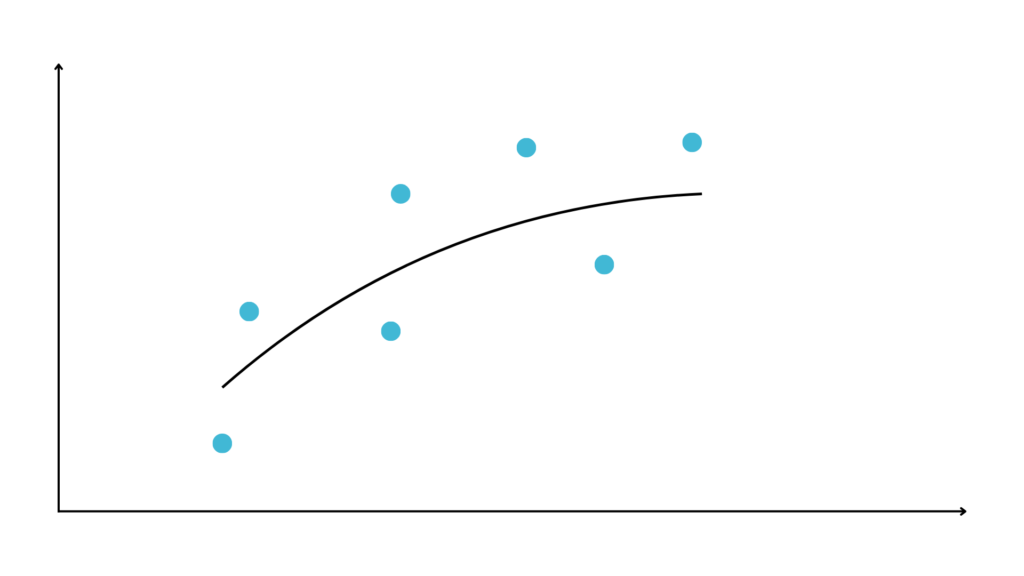
This is the ideal line we want to fit to the training data.
However, since we don’t know the exact formula, we choose two machine learning models to do the job.
What is bias?
We use linear regression to fit a straight line to the training data.
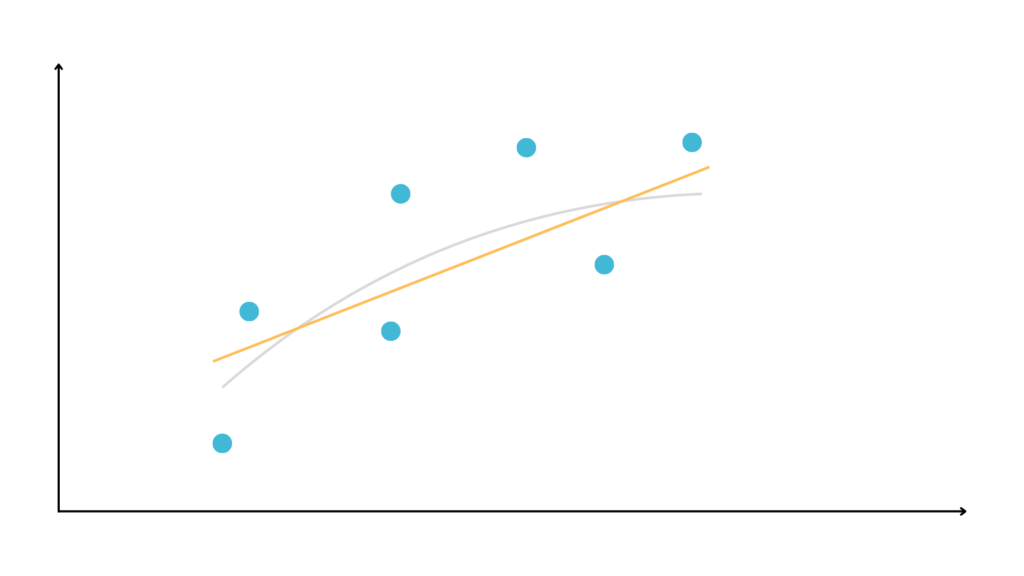
Since linear regression assumes the relationships between the variables is linear but in this case it’s not, it can be good but not perfect.
The incapacity of a model to fit the data is called bias.
Our first model has a relatively high bias.
Now, let’s build another model, that looks like this.

This model perfectly fits the training data, so it has 0 bias.
When a model like the first one is too simple, it doesn’t properly learn the relationship between the input and output variables.
This phenomenon is called underfitting.
What is variance?
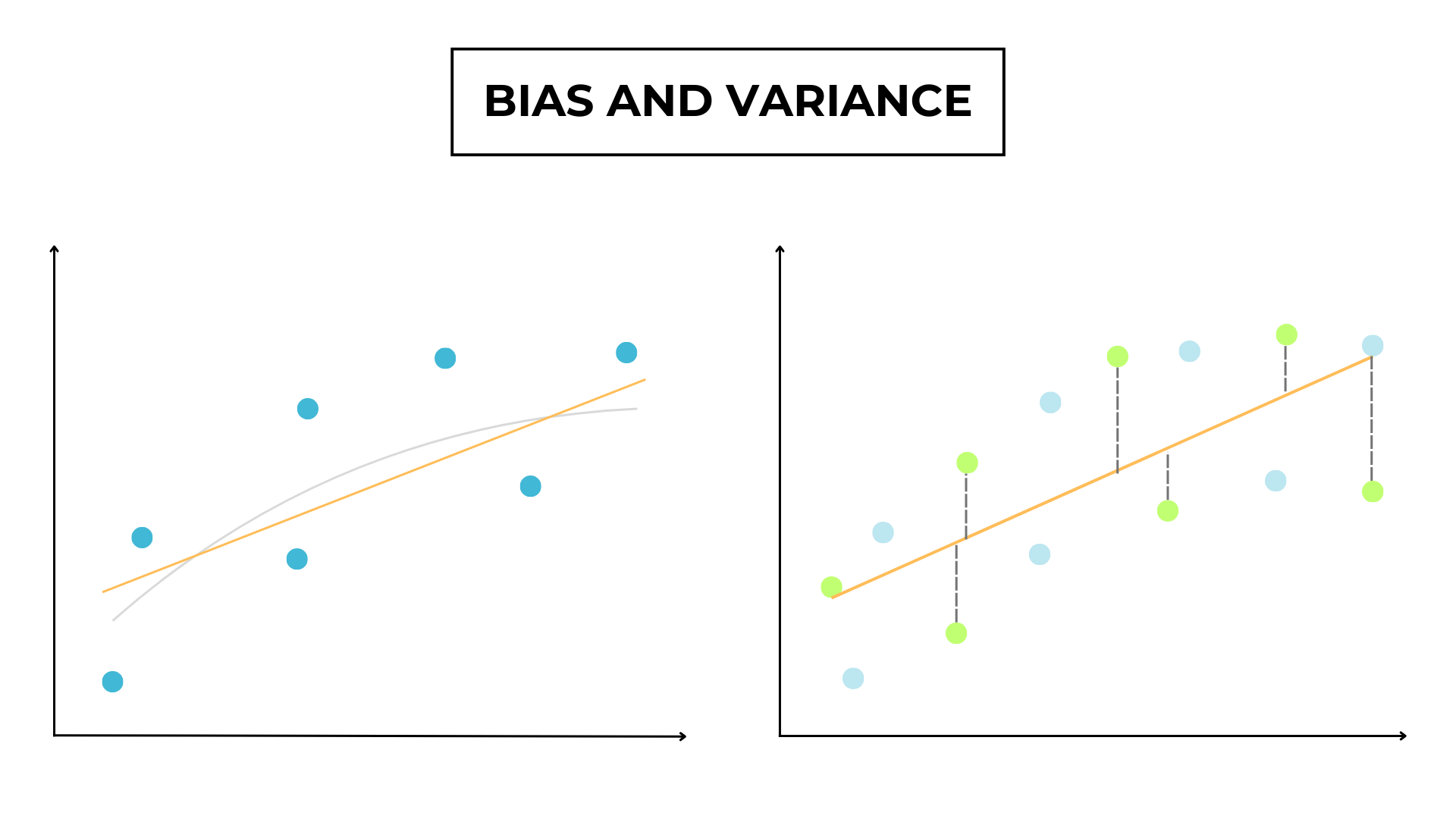
After building the 2 models, we want to calculate their accuracy on the test dataset.
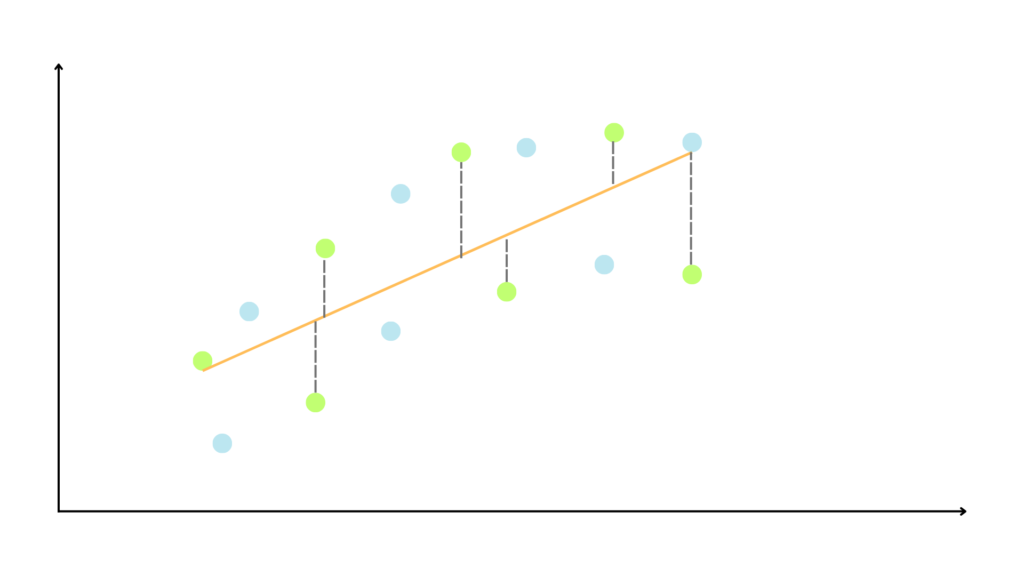
As you can see, the first model has quite good predictions, and they are consistent throughout the datasets.
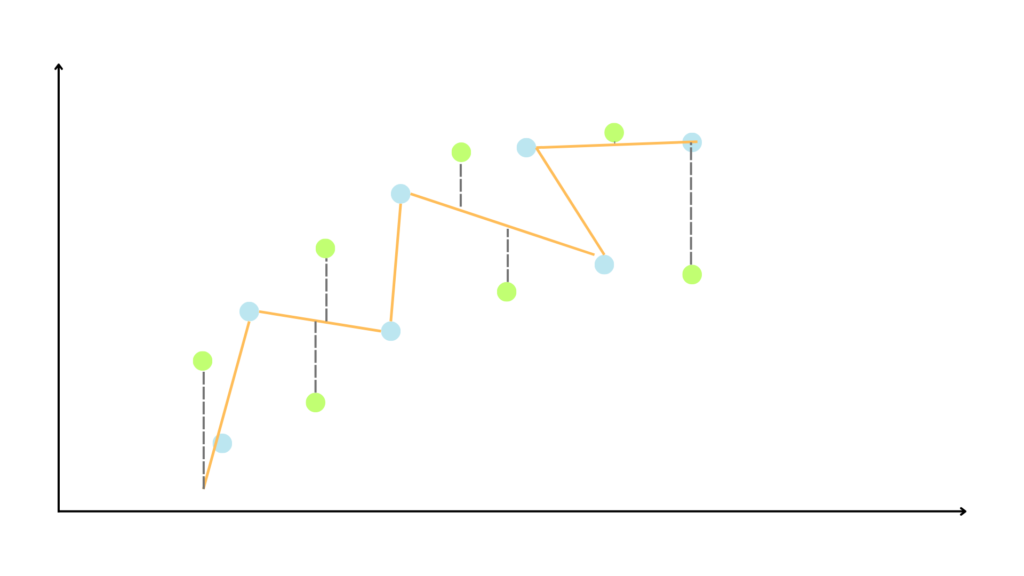
While the second model performs perfectly in the training data, it performs poorly in the validation dataset.
The difference between the error in the training and testing data is called variance.
The first model has low variance, while the second model has a high variance.
When a model, like the second one, is too complex, it tends to “bind” too much to the training dataset. Consequently, it doesn’t generalize and performs poorly in the testing dataset.
This phenomenon is called overfitting.