Table of Contents
What are categorical features – recap
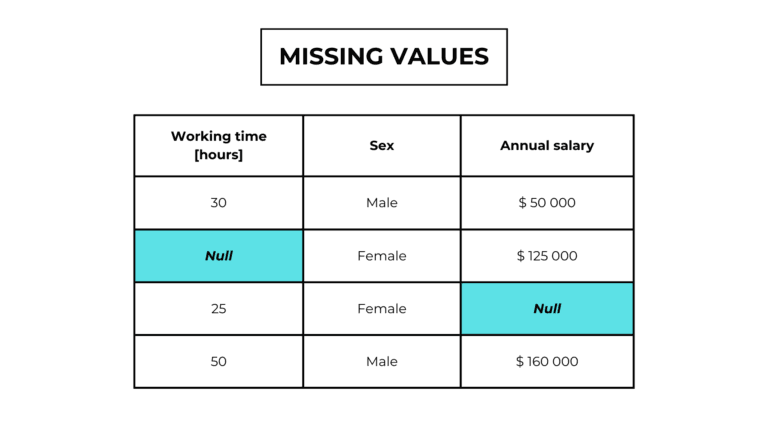
In categorical features, measurements can assimilate a number of limited and fixed values, called “categories“.
There are 2 types of categorical features:
- Ordinal data have a qualitative order.
ex. bad, mid, good… - Nominal data don’t have a qualitative order.
ex. red, green, blue…
Why can’t most ML models deal with categorical values?
Artificial intelligence models function thanks to mathematical formulas and algorithms.
Take for example the linear regression algorithm.
We have to use the formula y = x · m + b to predict an output, where m and b are two parameters (numbers) and x is the input.
How can we multiply the input “male” by 1.99 and then add 6.3?
It’s impossible and fun to think of.
What is encoding?
Data encoding is a feature engineering technique that converts categorical features into numerical features to feed them into the model.
Problem statement
We have a medical dataset and we want to predict the probability of a patient experiencing headaches.
| Sex | Sleep quality | Country | Headache (%) |
|---|---|---|---|
| Male | Good | USA | Sleep Quality |
| Female | Average | Lebanon | 72 |
| Male | Bad | Italy | 85 |
| Female | Good | USA | 25 |
To implement the categorical encoding techniques in Python, I’ll use a library created by scikit-learn called “Category Encoders“.
Ordinal encoding
We assign an integer value to each category of the feature we’re trying to convert.
| Sleep Quality | Sleep Quality Encoded |
|---|---|
| Good | 3 |
| Average | 2 |
| Bad | 1 |
When to use ordinal encoding?
Since we get an ordered list of values, our model interprets high indexes as high values.
So we should use ordinal encoding for ordinal data where the categories have a meaningful order, like the Sleep Quality column.
Ordinal encoding vs label encoding?
Label encoding is another encoding technique. It works exactly like ordinal encoding, but it is used for target features.
Python implementation
from sklearn.preprocessing import OrdinalEncoder
X = pandas.DataFrame(
{"Sleep_Quality" : ["Good", "Average", "Bad", "Good"]}
)
encoder = OrdinalEncoder(categories=[['Bad','Average','Good']]) # with the categories parameter we can input the order of the values
encoded_X = encoder.fit_transform(X)
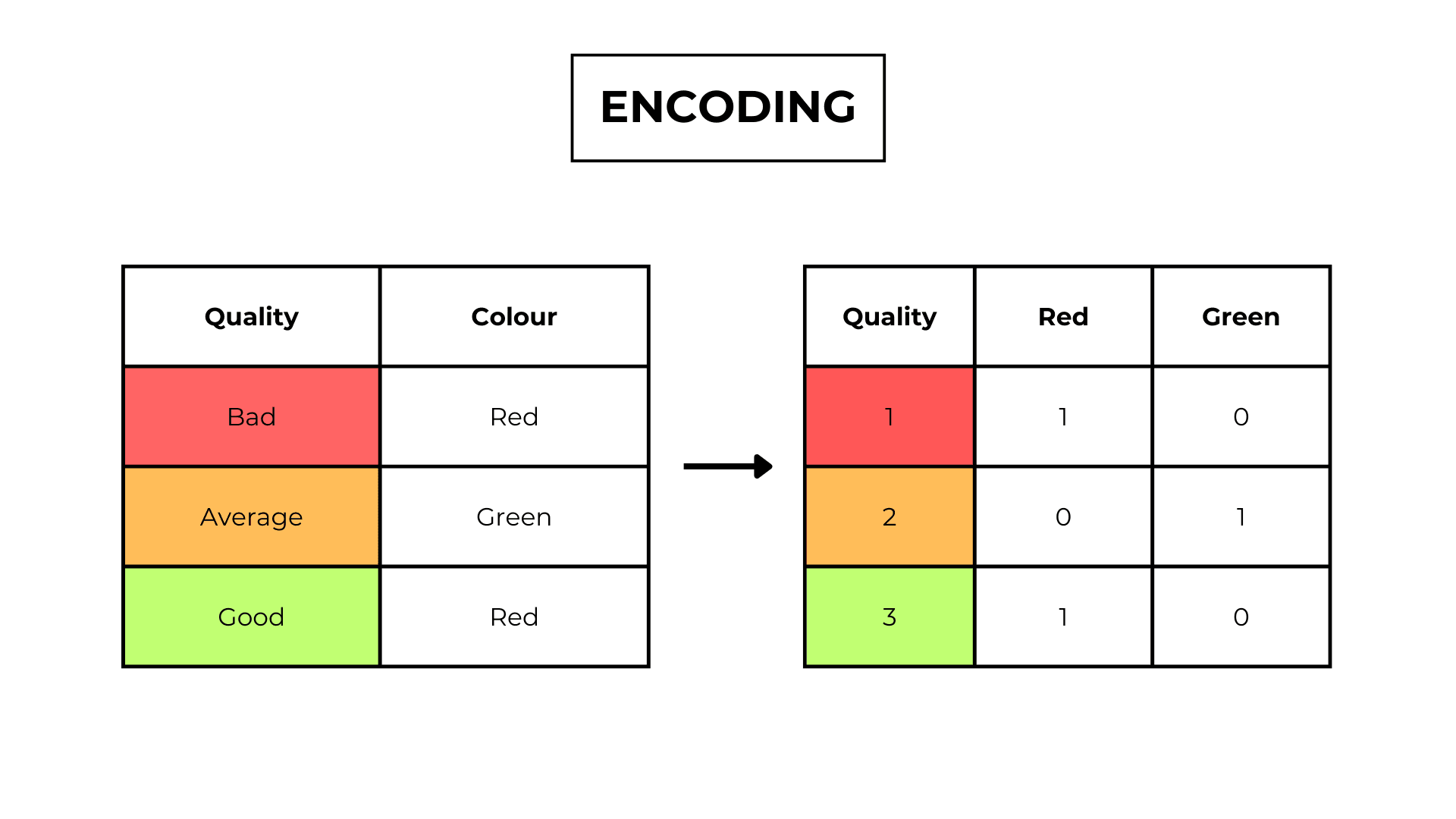
One-hot encoding
For each category in the feature, we create a new column.
If an input belongs to category x, the value of column “x” will be 1.
If not the value will be 0.
| Sex | Male | Female |
|---|---|---|
| Male | 1 | 0 |
| Female | 0 | 1 |
| Male | 1 | 0 |
| Female | 0 | 1 |
When to use one-hot encoding?
We should use one-hot encoding when:
- Our categories don’t have a meaningful order.
- There aren’t too many categories. This is because one-hot encoding increases the dimensionality of the dataset, and we want our program to be as efficient as possible.
Python implementation
from category_encoders import OneHotEncoder
X = pandas.DataFrame(
{"Sex" : ["male", "female", "male", "female"]}
)
encoder = OneHotEncoder()
encoded_X = encoder.fit_transform(X)
Dummy encoding
Dummy encoding works like one-hot encoding, but it creates n – 1 number of new features.
| Sex | Male | Female |
|---|---|---|
| Male | 1 | 0 |
| Female | 0 | 1 |
| Male | 1 | 0 |
| Female | 0 | 1 |
This is the output of the one-hot encoding. Even if we remove the female column, we can still distinguish a case where the value is female: when x[Male] = 0.
So we can drop one new feature. The model will recognise its pattern and we’ll save computational space with 1 less feature.
Binary encoding
The binary encoding algorithm works as follows:
- Encode the feature with ordinal encoding.
- Convert each integer into binary code.
- Report each binary code digit in a new column.
| Country | Ordinal encoding | Binary column 21 | Binary column 20 |
|---|---|---|---|
| USA | 1 | 0 | 1 |
| Lebanon | 2 | 1 | 0 |
| Italy | 3 | 1 | 1 |
When to use binary encoding?
We should use binary encoding when:
- Our categories don’t have a meaningful order (like in one-hot encoding).
- We have a high number of categories.
In this case, the country column fits the best.
To convert 195 countries using one-hot encoding we would need to add 195 features! With binary encoding, only 9.
Python implementation
from category_encoders import BinaryEncoder
X = pandas.DataFrame(
{"Country" : ["USA", "Italy", "Lebanon", "USA"]}
)
encoder = BinaryEncoder()
encoded_X = encoder.fit_transform(X)
Frequency encoding
In frequency encoding, the algorithm replaces each category with the number of times that category appears in the training dataset.
When to use frequency encoding?
We should use frequency encoding when the frequency of a category can be useful in predicting the target.
| Country | Country encoded |
|---|---|
| USA | 2 |
| Lebanon | 1 |
| Italy | 1 |
| USA | 2 |
As you can see, 2 categories have the same value if they appear the same N of times. This is a flaw of frequency encoding.
Python implementation
X = pandas.DataFrame(
{"Country" : ["USA", "Italy", "Lebanon", "USA"]}
)
frequency_encoder = X.value_counts().to_dict()
encoded_X = X.map(frequency_encoder)
Target encoding
The target (or mean) encoding algorithm replaces each category with the mean y of samples in that category.
| Sleep Quality | Headache (%) | Sleep Quality encoded |
|---|---|---|
| Good | 10 | (10 + 25) / 2 = 17.5 |
| Average | 72 | 72 |
| Bad | 85 | 85 |
| Average | 25 | 17.5 |
Python implementation
from category_encoders import TargetEncoder
X = pandas.DataFrame(
{"Country" : ["USA", "Italy", "Lebanon", "USA"]}
)
y = pandas.DataFrame(
{"Headache" : [10, 72, 85, 25]}
)
encoder = TargetEncoder()
encoded_X = encoder.fit_transform(X, y)